Introduction
In today’s digital-first world, system downtime is no longer just a technical issue—it directly impacts revenue, customer trust, and business continuity. Modern applications are distributed, cloud-native, and highly dynamic, making reliability more complex than ever before.
Organizations running microservices, Kubernetes clusters, and multi-cloud environments need more than traditional operations practices. They need a structured engineering approach that focuses on reliability, automation, monitoring, and rapid incident response.
This is where an SRE Consultant plays a critical role. Site Reliability Engineering (SRE) brings software engineering practices into infrastructure and operations to ensure systems remain highly available, observable, and resilient.
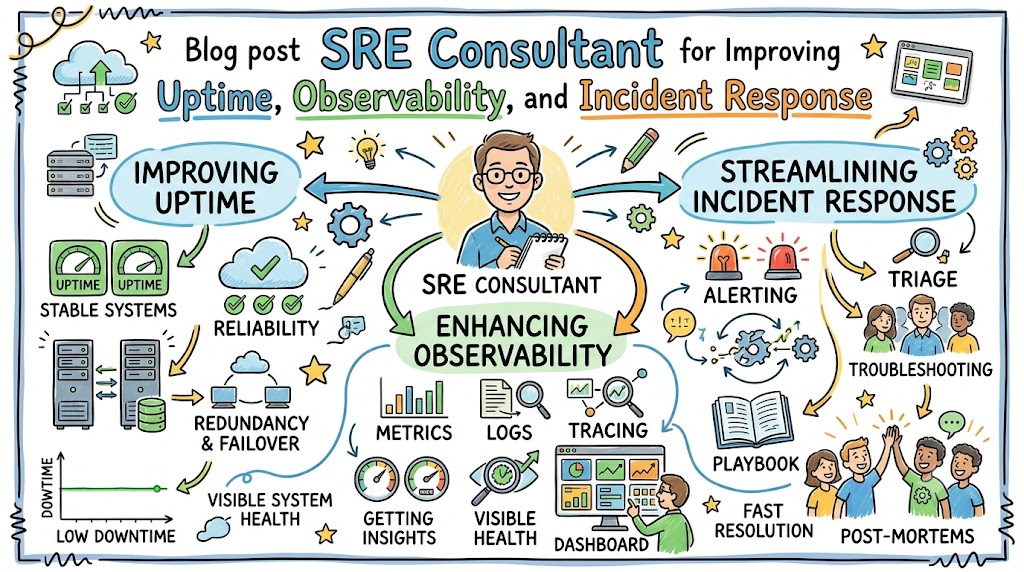
An experienced SRE Consultant helps organizations improve uptime, build strong observability systems, and design effective incident response strategies that minimize downtime and improve user experience.
Rajesh Kumar has extensive expertise in DevOps, Site Reliability Engineering, Kubernetes, DevSecOps, Platform Engineering, CI/CD, GitOps, Terraform, Jenkins, Docker Kubernetes Training, and cloud automation. His approach focuses on real-world production challenges and enterprise-scale solutions. You can learn more at https://www.rajeshkumar.xyz/.
Who Is Rajesh Kumar?
Rajesh Kumar is a seasoned technology trainer and consultant specializing in modern cloud-native engineering practices. He works with enterprises and engineering teams to improve software delivery, reliability, automation, and cloud operations.
His expertise includes:
- DevOps Trainer and DevOps Consultant
- SRE Trainer and SRE Consultant
- Kubernetes Trainer and Kubernetes Corporate Training
- DevSecOps Trainer and DevSecOps Corporate Training
- Platform Engineering Consultant
- Cloud DevOps Consultant and AWS DevOps Consultant
- CI/CD Pipeline Training and automation
- GitOps Training for modern infrastructure
- Terraform Training for Infrastructure as Code
- Jenkins Training for CI/CD automation
- Docker Kubernetes Training for containerized systems
His training approach emphasizes hands-on implementation, production readiness, and solving real operational challenges faced by engineering teams.
What Does an SRE Consultant Do?
An SRE Consultant helps organizations design, implement, and improve systems that ensure high availability and reliability in production environments.
Unlike traditional operations roles, an SRE Consultant focuses on engineering-driven solutions such as automation, observability, and measurable reliability goals.
Key responsibilities include:
- Improving system uptime and availability
- Designing observability and monitoring systems
- Enhancing incident detection and response processes
- Implementing Service Level Objectives (SLOs)
- Reducing mean time to recovery (MTTR)
- Automating operational workflows
- Strengthening production reliability
- Optimizing cloud infrastructure performance
Why Uptime Is Critical for Modern Systems
System uptime is one of the most important indicators of service reliability. Even a few minutes of downtime can lead to:
- Revenue loss
- Customer dissatisfaction
- SLA violations
- Reputation damage
- Operational disruptions
An SRE Consultant ensures that systems are designed for resilience using engineering best practices.
Key strategies to improve uptime:
- Redundant system architecture
- Auto-scaling infrastructure
- Load balancing
- Failover mechanisms
- Health checks and self-healing systems
- Continuous monitoring
Observability: The Foundation of Reliability
Observability goes beyond traditional monitoring. It allows engineering teams to understand system behavior through metrics, logs, and traces.
An SRE Consultant helps implement full-stack observability to ensure systems are transparent and diagnosable.
Core components of observability:
1. Metrics
Quantitative measurements like CPU usage, latency, and error rates.
2. Logs
Detailed event records that help diagnose system behavior.
3. Traces
End-to-end tracking of requests across distributed systems.
Benefits of observability:
- Faster troubleshooting
- Early detection of issues
- Improved system understanding
- Better performance optimization
- Reduced downtime
Incident Response and Management
Efficient incident response is essential for minimizing downtime and maintaining customer trust. An SRE Consultant helps organizations build structured incident management processes.
Incident response lifecycle:
1. Detection
Identifying issues through monitoring and alerting systems.
2. Response
Assigning teams and initiating mitigation steps.
3. Investigation
Analyzing root causes using logs, metrics, and traces.
4. Resolution
Fixing the issue and restoring normal operations.
5. Post-Incident Review
Documenting lessons learned and improving systems.
Key goals of incident management:
- Reduce MTTR (Mean Time to Recovery)
- Improve communication during incidents
- Prevent recurring issues
- Strengthen system resilience
SRE Consultant for Enterprise Systems
Large-scale enterprise environments require structured reliability engineering practices. An SRE Consultant helps organizations implement scalable solutions that work across distributed systems and cloud platforms.
Enterprise focus areas:
- Multi-cloud reliability strategies
- Kubernetes production stability
- CI/CD pipeline reliability
- Infrastructure automation
- Disaster recovery planning
- Performance optimization
- Compliance and operational governance
SRE and DevOps: Working Together
While DevOps focuses on speed and collaboration, SRE ensures that speed does not compromise reliability.
DevOps emphasizes:
- Continuous delivery
- Automation
- Collaboration
- Agile deployment
SRE emphasizes:
- Reliability engineering
- Monitoring and observability
- Incident management
- Performance optimization
Together, they create a balanced approach to software delivery and operations.
Kubernetes and SRE Practices
Kubernetes has become a standard platform for running cloud-native applications. However, managing Kubernetes at scale requires strong reliability engineering practices.
An SRE Consultant helps teams improve Kubernetes reliability through:
- Pod health monitoring
- Auto-healing workloads
- Resource optimization
- Cluster scaling strategies
- Rolling updates and rollback mechanisms
- Network reliability management
A strong Kubernetes foundation improves overall system uptime and stability.
CI/CD and Reliability Engineering
CI/CD pipelines play a critical role in production stability. Poorly designed pipelines can introduce instability and downtime.
An SRE Consultant improves CI/CD reliability by implementing:
- Automated testing strategies
- Deployment validation
- Canary releases
- Blue-green deployments
- Rollback mechanisms
- Pipeline monitoring
Training like CI/CD Pipeline Training ensures teams understand how to build reliable release pipelines.
Infrastructure as Code for Reliable Systems
Infrastructure consistency is essential for system reliability. Manual configuration often leads to errors and downtime.
With Terraform Training, teams learn how to:
- Automate infrastructure provisioning
- Maintain version-controlled infrastructure
- Reduce configuration drift
- Improve scalability
- Ensure consistent environments
Infrastructure as Code is a key pillar of modern SRE practices.
DevSecOps and Reliability
Security and reliability are closely connected. Vulnerabilities and misconfigurations can directly impact system uptime.
DevSecOps practices help improve reliability by:
- Securing CI/CD pipelines
- Automating vulnerability detection
- Enforcing security policies
- Monitoring threats in real time
- Ensuring compliance readiness
Tools and Technologies Covered
| Area | Tools / Topics | Business Value |
|---|---|---|
| Monitoring | Prometheus, Grafana | Real-time system visibility |
| Logging | ELK Stack | Faster troubleshooting |
| Tracing | OpenTelemetry | End-to-end request tracking |
| CI/CD | Jenkins, GitHub Actions | Reliable deployments |
| Infrastructure | Terraform | Consistent environments |
| Containers | Docker, Kubernetes | Scalable applications |
| GitOps | Argo CD | Controlled deployments |
| Cloud | AWS, Azure, GCP | Scalable infrastructure |
| DevSecOps | Security automation tools | Safer systems |
| SRE Practices | SLO, SLI, error budgets | Improved reliability |
Why Choose Rajesh Kumar as an SRE Consultant
Organizations choose experienced consultants who can combine theory with real-world execution.
Key strengths include:
- Deep experience in DevOps and SRE practices
- Strong focus on production reliability
- Hands-on approach to training and consulting
- Expertise in Kubernetes and cloud-native systems
- Practical incident management experience
- Strong automation and monitoring knowledge
- Enterprise-scale system understanding
- Focus on measurable operational improvements
His approach helps teams build long-term reliability capabilities rather than short-term fixes.
Best Fit Audience
This consulting approach is ideal for:
- DevOps Engineers
- SRE Engineers
- Cloud Engineers
- Platform Engineers
- IT Operations Teams
- Site Reliability Teams
- Enterprise Architecture Teams
- Startup Engineering Teams
- Cloud Migration Teams
- Digital Transformation Teams
Business Benefits of SRE Consulting
Organizations working with an SRE Consultant typically experience:
- Higher system uptime
- Faster incident resolution
- Improved observability
- Better automation coverage
- Reduced operational risks
- Stronger cloud reliability
- Improved deployment stability
- Enhanced customer experience
- Lower downtime costs
- Better engineering efficiency
FAQs
1. What does an SRE Consultant do?
An SRE Consultant helps organizations improve system reliability, uptime, observability, and incident response using engineering and automation practices.
2. Why is SRE important for modern systems?
SRE ensures systems remain highly available and resilient while supporting rapid software delivery in cloud-native environments.
3. How does SRE improve incident response?
It introduces structured processes, automation, and monitoring systems that reduce detection and recovery time during incidents.
4. Who should hire an SRE Consultant?
Enterprises, startups, and engineering teams managing cloud-native or distributed systems should hire an SRE Consultant.
5. How does observability support SRE?
Observability provides insights into system behavior through metrics, logs, and traces, enabling faster troubleshooting and improved reliability.
Conclusion
Modern digital systems demand high availability, fast recovery, and strong operational resilience. An experienced SRE Consultant helps organizations achieve these goals by improving uptime, building observability frameworks, and strengthening incident response strategies.
By combining DevOps, Kubernetes, CI/CD, Infrastructure as Code, and DevSecOps practices, Site Reliability Engineering enables organizations to build scalable and reliable systems that support continuous innovation.
To explore professional training and consulting services, visit https://www.rajeshkumar.xyz/.