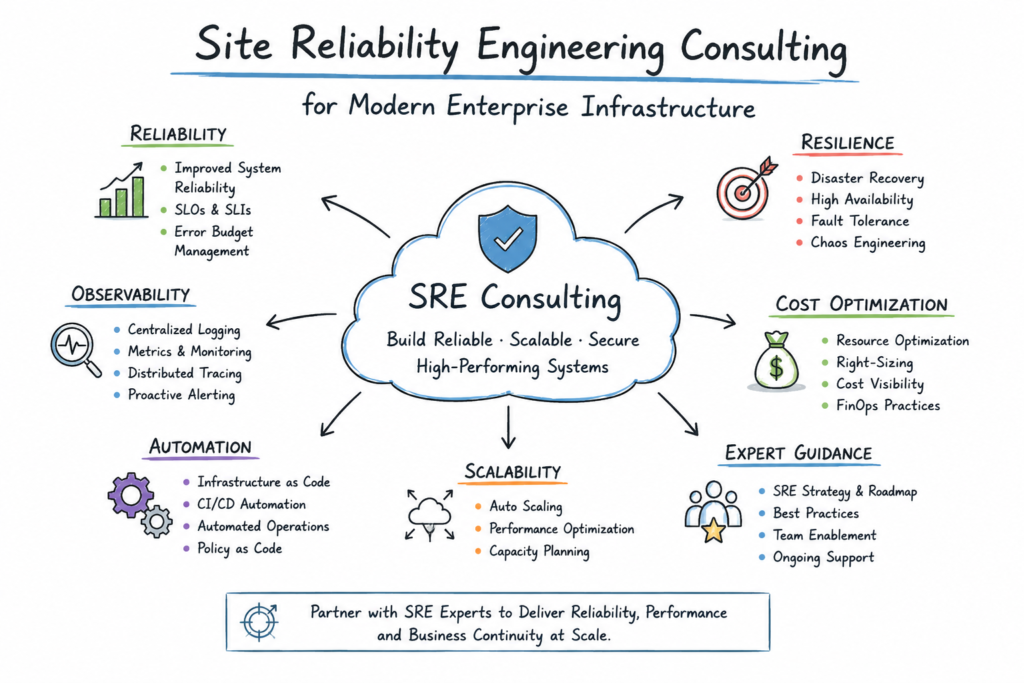
Introduction
Modern enterprises depend on highly available digital systems that must perform reliably under constant load, rapid scaling, and complex distributed architectures. As infrastructure becomes more cloud-native, ensuring uptime and performance requires a structured engineering approach rather than traditional IT operations.
Site Reliability Engineering (SRE) provides that approach by combining software engineering with operations to build reliable, scalable, and automated systems.
Cotocus offers Site Reliability Engineering consulting services that help enterprises design, implement, and optimize resilient infrastructure for modern digital environments.
Reference: Cotocus Official Website
Why Site Reliability Engineering is Critical for Modern Enterprises
Enterprises today operate in environments where downtime directly impacts revenue, customer trust, and brand reputation.
Common challenges include:
- Frequent production incidents
- Lack of reliability metrics and visibility
- Slow incident response times
- Poor system observability
- Inefficient scaling under high load
- Manual operational processes
SRE addresses these challenges by introducing measurable reliability standards and automation-driven operations.
What is Site Reliability Engineering Consulting
SRE consulting focuses on designing and improving system reliability using engineering principles.
Key components include:
- Defining SLIs (Service Level Indicators)
- Establishing SLOs (Service Level Objectives)
- Managing error budgets for system reliability
- Designing observability frameworks
- Automating incident response workflows
- Capacity planning and performance tuning
The goal is to ensure stable, scalable, and self-healing infrastructure systems.
Cotocus Approach to SRE Consulting
Cotocus follows a structured methodology to implement enterprise-grade SRE practices.
Assessment Phase
- Infrastructure and application analysis
- Incident pattern evaluation
- Monitoring maturity assessment
Design Phase
- SLI/SLO framework definition
- Reliability architecture planning
- Alerting strategy design
Implementation Phase
- Observability stack setup
- Incident management automation
- Logging, metrics, and tracing integration
Optimization Phase
- Performance tuning
- Scaling improvements
- Continuous reliability enhancement
This ensures enterprises achieve predictable and measurable system stability.
Core Pillars of Site Reliability Engineering
SRE consulting is built on five foundational pillars:
Reliability Engineering
Ensures systems remain stable even under failures and high demand.
Observability
Provides deep visibility into system health using logs, metrics, and traces.
Incident Management
Reduces downtime through structured response and automation.
Automation
Eliminates repetitive operational tasks to improve efficiency.
Capacity Planning
Ensures infrastructure can handle future growth without degradation.
SRE and DevOps Integration
SRE and DevOps work together to improve both delivery speed and system reliability.
Key integrations include:
- CI/CD pipeline reliability validation
- Infrastructure as Code (IaC) adoption
- Automated rollback strategies
- Continuous monitoring in production environments
- Shared ownership between development and operations teams
This ensures faster releases without compromising system stability.
Observability in Modern Enterprise Infrastructure
Observability is a core requirement in SRE consulting.
It includes:
- Centralized logging systems
- Real-time metrics dashboards
- Distributed tracing systems
- Anomaly detection mechanisms
- Alerting and notification systems
This enables proactive issue detection before they impact end users.
Incident Response and Automation
Efficient incident management is essential for minimizing downtime.
SRE consulting helps enterprises implement:
- Automated incident detection systems
- On-call and escalation workflows
- Runbook automation
- Root cause analysis frameworks
- Post-incident reviews and improvements
This reduces Mean Time to Recovery (MTTR) significantly.
Scalability and Performance Optimization
Modern infrastructure must handle dynamic workloads efficiently.
SRE consulting enables:
- Auto-scaling configurations
- Load balancing strategies
- Resource optimization
- Traffic management policies
- Performance benchmarking and tuning
This ensures consistent performance during peak demand.
Security and Reliability Alignment
Security and reliability must work together in enterprise systems.
SRE consulting supports:
- Secure infrastructure design
- Identity and access management (IAM)
- Compliance-aligned operations
- Vulnerability monitoring systems
- Policy-based governance
This ensures systems are both secure and resilient.
Business Benefits of SRE Consulting Services
Enterprises adopting SRE consulting experience:
- Higher system uptime and availability
- Faster incident resolution
- Improved system performance
- Reduced operational costs
- Better scalability under load
- Increased customer satisfaction
These improvements directly support business continuity and growth.
Traditional IT vs SRE Model
| Aspect | Traditional IT Operations | SRE Model |
|---|---|---|
| Approach | Reactive support | Engineering-driven reliability |
| Monitoring | Basic alerts | Full observability |
| Scaling | Manual intervention | Automated scaling |
| Reliability | Undefined metrics | SLO-based system |
| Incident Response | Slow recovery | Automated workflows |
| Infrastructure | Static systems | Cloud-native dynamic systems |
Service Mapping Table
| Service Area | Enterprise Challenge | SRE Consulting Approach | Business Outcome |
|---|---|---|---|
| Incident Management | Slow recovery | Automation + runbooks | Faster resolution |
| Monitoring | Limited visibility | Observability stack | Early detection |
| Scaling | System overload | Auto-scaling design | Stable performance |
| Reliability | Frequent downtime | SLO framework | High uptime |
| Capacity Planning | Resource inefficiency | Predictive planning | Optimized usage |
| Automation | Manual operations | Workflow automation | Reduced workload |
Why Enterprises Choose Cotocus
Organizations choose Cotocus for SRE consulting because of:
- Strong expertise in DevOps, cloud, and reliability engineering
- Practical, real-world implementation approach
- Deep focus on automation and observability
- Enterprise-scale infrastructure transformation experience
- Integration of DevOps, Kubernetes, and cloud-native practices
- Combined consulting and corporate training capabilities
- End-to-end digital transformation support
FAQs
1. What is Site Reliability Engineering consulting?
It helps enterprises build reliable and scalable infrastructure using engineering and automation practices.
2. Why is SRE important for enterprises?
It improves uptime, performance, and system stability.
3. What are SLIs and SLOs?
SLIs measure system performance, while SLOs define reliability targets.
4. How does SRE reduce downtime?
Through automation, observability, and structured incident response.
5. What is observability in SRE?
It is the ability to understand system behavior using logs, metrics, and traces.
6. Is SRE part of DevOps?
Yes, it complements DevOps by focusing on reliability.
7. How does SRE improve scalability?
Through auto-scaling and performance optimization.
8. What tools are used in SRE?
Monitoring, logging, alerting, and automation tools.
9. How does Cotocus support SRE transformation?
Through consulting, implementation, and training services.
10. Which industries need SRE consulting?
SaaS, fintech, healthcare, e-commerce, and enterprise IT.
Conclusion
Site Reliability Engineering consulting is essential for modern enterprises that require highly available, scalable, and resilient infrastructure systems. Cotocus helps organizations implement SRE practices through observability, automation, and reliability engineering to ensure stable and high-performing enterprise systems. Reference: Cotocus Official Website For enterprises aiming to modernize infrastructure and improve operational resilience, Cotocus delivers a trusted and future-ready SRE consulting approach.